Coarse-to-fine 3D clothed human reconstruction using peeled semantic segmentation context
Snehith Goud Routhu, Sai Sagar Jinka and Avinash Sharma
Abstract
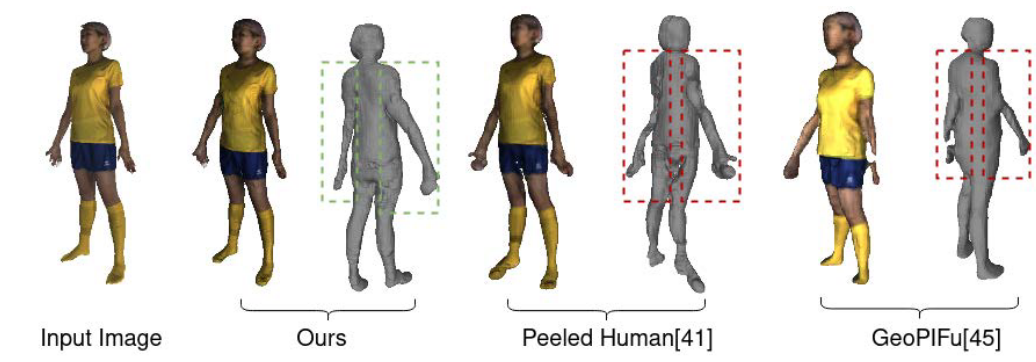
3D reconstruction of human body model from a monocular images is a desired research problem in computer vision with applications in various fields such as gaming, AR/VR and virtual try on industries. PeeledHuman proposed a sparse non-parametric 2D representation that can handle self-occlusion. However, the key limitation of the PeeledHuman model is that the predicted depth maps of self-occluded parts are sparse and noisy, and hence after back-projection lead to distorted body parts and sometimes with discontinuity between them. We propose Peeled Segmentation map representation in a coarse-to-fine refinement framework which consist of a cascade three networks namely, PeelGAN, PSegGAN and RefGAN. We use original PeeledHuman as baseline model to predict initial coarse estimation of peeled depth maps from input RGB image. These peeled maps are subsequently fed as input along with monocular RGB image to our novel PSegGAN which predict Peeled Segmentation maps in a generative fashion. Finally, we feed these peeled segmentation maps as additional context along with monocular input image to our RefGAN which predicts the refined peeled RBG and Depth maps. This also provides an additional output of 3D semantic segmentation of the reconstructed shape.
Results
Comparison
Downloads
- Paper
- Supplementary Material
- Code (Coming Soon)
Contact
BibTeX
@inbook{10.1145/3490035.3490293,
author = {Routhu, Snehith Goud and Jinka, Sai Sagar and Sharma, Avinash},
title = {Coarse-to-Fine 3D Clothed Human Reconstruction Using Peeled Semantic Segmentation Context},
year = {2021},
isbn = {9781450375962},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3490035.3490293},
abstract = {3D reconstruction of human body model from a monocular image is an under-constrained and challenging yet desired research problem in computer vision. Recently proposed multi-layered shape representation called PeeledHuman attempted a sparse non-parametric 2D representation that can handle severe self-occlusion. However, the key limitation of their PeeledHuman model is that the predicted depth maps of self-occluded parts are sparse and noisy, and hence after back-projection lead to distorted body parts and sometimes with discontinuity between them. In this work, proposed to introduce Peeled Segmentation map representation in a coarse-to-fine refinement framework which consist of a cascade three networks namely, PeelGAN, PSegGAN and RefGAN. At first, we use original PeeledHuman as baseline model to predict initial coarse estimation of peeled depth maps from input RGB image. These peeled maps are subsequently fed as input along with monocular RGB image to our novel PSegGAN which predict Peeled Segmentation maps in a generative fashion. Finally, we feed these peeled segmentation maps as additional context along with monocular input image to our RefGAN which predicts the refined peeled RBG and Depth maps. This also provides an additional output of 3D semantic segmentation of the reconstructed shape. We perform thorough empirical evaluation over four publicly available datasets to demonstrate superiority of our model.},
booktitle = {Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing},
articleno = {34},
numpages = {9}
}